

The goal of this activity was to investigate an architecture for adaptive optics real-time control where the system is based on a standard CPU server accelerated with GPUs. The solution we have developed goes beyond all the limitations of classical GPU computing (throughput oriented) and relies on a never ending or persistent kernel enabling time determinism (real-time) on such platform. The point of using persistent kernel is to bypass completely the CPU utilization, including for synchronization tasks
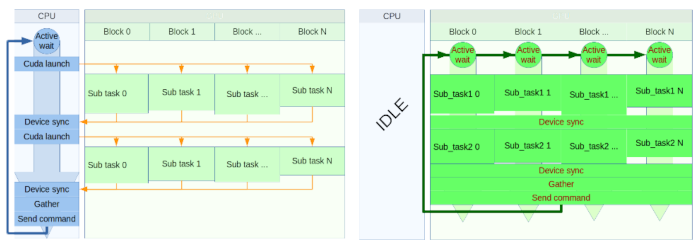
However the solution introduces a huge constraint in the implementation, it does not allow the use of any existing standard library. Added to this is the necessity to use the correct number of blocks and threads to use 100% of the GPU capacities in terms of maximum number of blocks and threads per block.
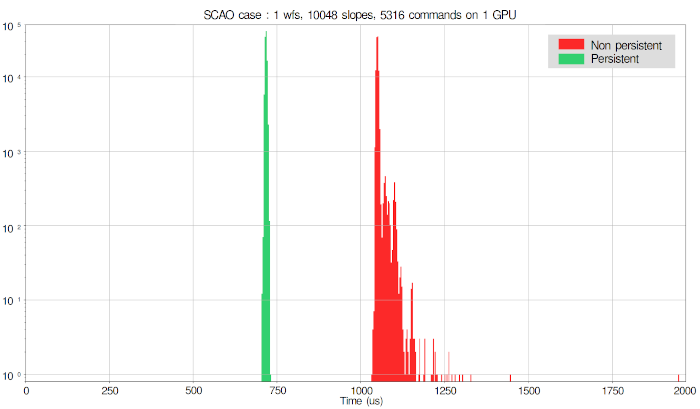
The obtained results show that extreme stability and maximum performance can be achieved when removing kernel launches and executing a single pipeline. In the histogram below, we have evaluated the performance of our pipeline (MVM only) on a V100 GPU using persistent kernels.
Below are execution profiles of the persistent kernel approach as seen from the various clocks available in the system:
The performance were measured on two versions of the latest GPU architecture, both supporting the GPUdirect feature:
In this case, the problem scale corresponds to the ELT SCAO dimensioning, i.e. the largest problem scale for a single GPU system.

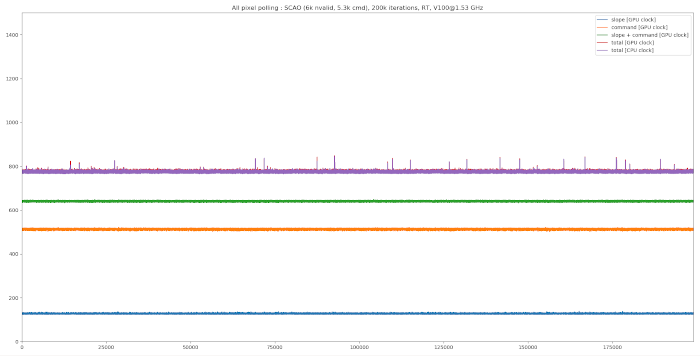
5 different timings are reported:
The first thing to be noticed is the extreme performance stability observed internally in the GPU. In this case, the data are transferred through a memcopy process from the host memory to the GPU and this seems to have a significant impact on performance stability as shown by variation observed in the total execution time as compared to what is obtained for the various steps individually.
On top of this, while the total time as seen from the GPU clocks is equal to the total time as seen from the host CPU process is equal in the case of the V100 it is significantly different in the case of the GV100. This seems to show that the actual clock frequency on the Tesla line of the product can be well handled, it is not the case for other lines of products and in particular for the Quadro, which evidence an important property of the GPU for real-time applications.