

The team at OdP has assembled a full scale demonstrator for an E-ELT first-light AO RTC, based on the GPU technology. Such facility, designed to drive in real-time the AO system, is composed of a real-time core, processing streaming data from sensors and controlling deformable optics, and a supervisor module, optimizing the control loop by providing updated versions of the control matrix at a regular rate depending on the observing conditions evolution.

This RTC prototype is designed to assess the system performance in various configurations from single conjugate AO for the E-ELT, i.e. about 10 Gb/s of streaming data from a single sensor and a required performance of about 100 GMAC/s; to the dimensioning of a MCAO system with 100 Gb/s of streaming data and 1.5 TMAC/s performance. Both concepts rely on the same architecture, the latter being a scaled version of the former.
We chose a very low level approach using a persistent kernel strategy on the GPUs to handle all the computation steps including pixel calibration, slopes and command vector computation. This approach simplifies the latency management by reducing the communication but led us to re-implement some GPUs standard features : communication mechanisms (guard, peer-to-peer), algorithms (generalized matrix-vector multiplication, reduce/all reduce) and new synchronization mechanisms on a multi node - multi GPUs system.
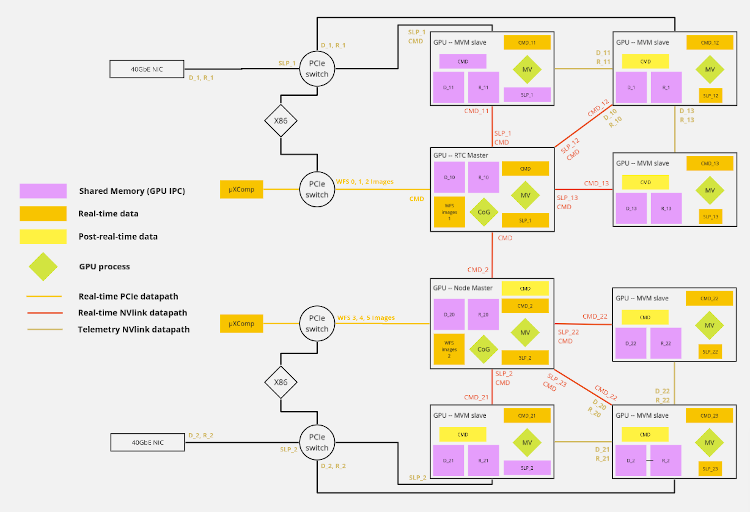
In order to assess the performance of the full AO RTC prototype under realistic conditions, we have concurrently implemented a real-time simulator able to feed the real-time core with data by emulating the sensors data transfer protocols and interacting with simulated deformable optics. The real-time simulator is able to deliver high precision simulated data and simulate the whole retro-action loop for the SCAO case, enabling a full scale / full feature test of the prototype.
The scalability of the AO pipeline on a multi-GPU platform was evaluated on this prototype (based on a DGX-1 sever with P100 Tesla GPUs)
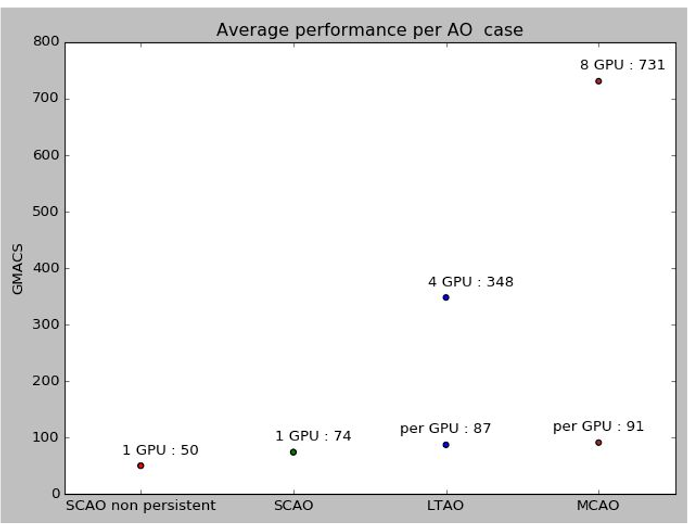
Looking at these results in terms of giga multiply-accumulate per second (GMAC/s), a better performance per GPU is obtained in the LTAO and MCAO case as compared to SCAO. Indeed, the LTAO case is 6 times larger in terms of number of operations than the SCAO case for a single MVM, which is again doubled in the case of a pseudo-open loop pipeline and is addressed with 4 GPUs. We would thus expect an average execution time 3 times larger, but the histogram shows that the pipeline is only 2.6 times slower. The amount of computations done by a single GPU is thus larger in the case of LTAO and allows to leverage more of the GPU memory bandwidth. In the case of MCAO, the problem scale is 3 times larger than in the LTAO case and is addressed by 8 GPUs,
If we look closer to these results and try to compare them to the GPU specifications the Tesla P100 has a theoretical memory bandwidth of 5760 Gb/s. The amount of data to be assimilated by the compute engines to perform the multiply-accumulates for a single iteration in the MCAO case is 60288 15316 2 4 = 7.3Gb.
Each iteration is performed in about 2.5ms which leads to a measured sustained memory bandwidth of 2954 Gb/s or 51% of the theoretical memory bandwidth as given and 77% of the sustained BW. Even though this probably requires some additional optimization, it shows that our approach is able to leverage most of the available bandwidth to execute the pipeline.